题目序号 385、43、616、49、6、556、555、553、271、249¶
385. Mini Parser¶
Given a nested list of integers represented as a string, implement a parser to deserialize it.
Each element is either an integer, or a list – whose elements may also be integers or other lists.
Note: You may assume that the string is well-formed:
String is non-empty. String does not contain white spaces. String contains only digits 0-9, [, - ,, ]. Example 1:
Given s = “324”,
You should return a NestedInteger object which contains a single integer 324. Example 2:
Given s = “[123,[456,[789]]]”,
Return a NestedInteger object containing a nested list with 2 elements:
- An integer containing value 123.
- A nested list containing two elements:
- An integer containing value 456.
- A nested list with one element:
- An integer containing value 789.
43. Multiply Strings¶
Given two non-negative integers num1 and num2 represented as strings, return the product of num1 and num2.
Note:
The length of both num1 and num2 is < 110. Both num1 and num2 contains only digits 0-9. Both num1 and num2 does not contain any leading zero. You must not use any built-in BigInteger library or convert the inputs to integer directly.
这道题目相关联的题目有 43 Multiply Strings 50 Pow(x, n) 65 Valid Number 66 Plus One 67 Add Binary 149 Max Points on a Line 166 Fraction to Recurring Decimal 168 Excel Sheet Column Title 171 Excel Sheet Column Number 172 Factorial Trailing Zeroes 179 Largest Number 224 Basic Calculator 227 Basic Calculator II 233 Number of Digit One 258 Add Digits 273 Integer to English Words 题解:就是让实现一个大整数乘法。
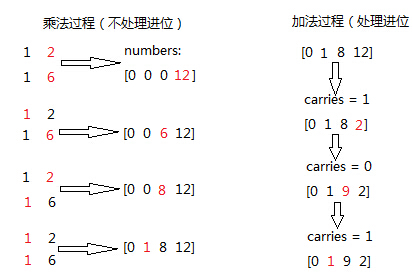
假设两个数num1和num2的长度分别是len1和len2,那么最后得到的答案,在最高位有进位的时候,就是len1+len2位,否则是len1+len2-1位。我们用数组numbers[len1+len2]存放最后的结果。
很关键的一点就是在做每位之间的乘法的时候不要处理进位,在做加法的时候同一处理进位。
class Solution:
# @param num1, a string
# @param num2, a string
# @return a string
def multiply(self, num1, num2):
if num1=='0' or num2=='0': return '0'
n,m = len(num1),len(num2)
num1 ,num2 = num1[::-1] , num2[::-1]
res=[0]*(n+m)
for i in range(0,n):
id = i
for j in range(0,m):
res[id] ,id = res[id]+int(num1[i]) * int(num2[j]),id+1
carry = 0
for i in range(0,n+m):
res[i] , carry =(res[i]+carry) % 10,(res[i]+carry) /10
ans=""
for i in xrange(n+m-1,-1,-1): ans += str(res[i])
for i in range(n+m):
if ans[i] != '0': break
return ans[i:]
class Solution:
# @param num1, a string
# @param num2, a string
# @return a string
def multiply(self, num1, num2):
num1 = num1[::-1]; num2 = num2[::-1]
arr = [0 for i in range(len(num1)+len(num2))]
for i in range(len(num1)):
for j in range(len(num2)):
arr[i+j] += int(num1[i]) * int(num2[j])
ans = []
for i in range(len(arr)):
digit = arr[i] % 10
carry = arr[i] / 10
if i < len(arr)-1:
arr[i+1] += carry
ans.insert(0, str(digit))
while ans[0] == '0' and len(ans) > 1:
del ans[0]
return ''.join(ans)
# may overflow
def multiply1(self, num1, num2):
return str(int(num1)*int(num2))
# may overflow
def multiply2(self, num1, num2):
res = 0
for i, d1 in enumerate(num1[::-1]):
tmp = int(d1)*(10**i)
for j, d2 in enumerate(num2[::-1]):
res += tmp * (int(d2)*(10**j))
return str(res)
# No overflow
def multiply(self, num1, num2):
res = [0] * (len(num1) + len(num2))
for i in xrange(len(num1)-1, -1, -1):
carry = 0
for j in xrange(len(num2)-1, -1, -1):
tmp = int(num1[i])*int(num2[j])+carry
# take care of the order of the next two lines
carry = (res[i+j+1] + tmp) // 10
res[i+j+1] = (res[i+j+1] + tmp) % 10
# or simply: carry, res[i+j+1] = divmod((res[i+j+1] + tmp), 10)
res[i] += carry
res = "".join(map(str, res))
return '0' if not res.lstrip("0") else res.lstrip("0")
616. Add Bold Tag in String¶
Given a string s and a list of strings dict, you need to add a closed pair of bold tag <b> and </b> to wrap the substrings in s that exist in dict. If two such substrings overlap, you need to wrap them together by only one pair of closed bold tag. Also, if two substrings wrapped by bold tags are consecutive, you need to combine them.
Example 1:
Input:
s = "abcxyz123"
dict = ["abc","123"]
Output:
"<b>abc</b>xyz<b>123</b>"
Example 2:
Input:
s = "aaabbcc"
dict = ["aaa","aab","bc"]
Output:
"<b>aaabbc</b>c"
Note:
The given dict won’t contain duplicates, and its length won’t exceed 100. All the strings in input have length in range [1, 1000].
题目大意: 给定字符串s和一组字符串dict,在s中寻找在dict中出现过的子串,并在其首位添加加粗标签。
如果两个子串相互重叠或者首位相连,将加粗标签进行合并。
- colored数组记录s中是否包含dict中字符串,若包含,将对应位置为‘1’,否则为‘0’
- 使用KMP字符串匹配算法找出s中包含的dict中字符串的所有位置,将对应colored置为‘1’
- 将colored中连续1用<b></b>包围
49. Group Anagrams¶
Given an array of strings, group anagrams together.
For example, given: [“eat”, “tea”, “tan”, “ate”, “nat”, “bat”], Return:
[
["ate", "eat","tea"],
["nat","tan"],
["bat"]
]
Note: All inputs will be in lower-case.
解法
这道题目的关键之处,其实就是怎么样判断两个字符串拥有相同的“字符集”,这样类型的判断通常有两种方法:
- 一种是对任意两个字符串进行比较,判断他们的字符集是否相同。这样的方法适用于字符串数量较小的情况,而第二种方法就是求出每个字符串的字符集,然后将所有字符串按照它们的字符集进行排序,这样拥有相同字符集的字符串就会处于相邻的位置。这样的方法适用于字符集较小的情况。在这里,我们不难发现,第二种方法会更适用于这道题目。
- 值得一提的是,第二种做法中求出每个字符串的字符集,实际上就是一种Hash策略(即对一个物体计算一个方便使用的数值来代表这个物体,并且拥有相同特性的物品计算出的数值会一定程度上相同,于是就可以利用这个数值来找到类似的物体),这也就是为什么Hash是这道题的标签之一的原因。
那么接下来只需要解决一些小的问题:
如何求每个字符串的字符集(即Hash值):这个问题的解决方法有很多种,笔者建议采取的是同样计算为一个字符串,这个字符串和原本字符串的组成字符是相同的,不过在内部所有字符都按照非递减的顺序排序,这样一方面容易求解,另外一方面也能够确保每个字符串的Hash值是唯一的。 不要忘记题目要求的每个由拥有相同“字符集”的字符串组成的集合内部也要按照字典序进行排序。 综上所述,这道题可以得到非常好的解决~当然,对于Hash值或者排序的方面还存在着一些可能的优化,这就有待读者自己去思考啦!
判断两个词是否是变形词,最简单的方法是将两个词按字母排序,看结果是否相同。这题中我们要将所有同为一个变形词词根的词归到一起,最快的方法则是用哈希表。所以这题就是结合哈希表和排序。我们将每个词排序后,根据这个键值,找到哈希表中相应的列表,并添加进去。为了满足题目字母顺序的要求,我们输出之前还要将每个列表按照内部的词排序一下。可以直接用Java的Collections.sort()这个API。
"""
def anagrams(self, strs):
dic = {}
for s in strs:
dic[tuple(sorted(s))] = dic.get(tuple(sorted(s)),[]) + [s]
res = []
[res.extend(item) for item in dic.values() if len(item) > 1]
return res
"""
# Here is an updated version, where the order in each inner group is maintained:
def groupAnagrams(self, strs):
dic = {}
for s in strs:
dic[tuple(sorted(s))] = dic.get(tuple(sorted(s)),[]) + [s]
return [sorted(item) for item in dic.values()]
6. ZigZag Conversion¶
The string “PAYPALISHIRING” is written in a zigzag pattern on a given number of rows like this: (you may want to display this pattern in a fixed font for better legibility)
P A H N
A P L S I I G
Y I R
And then read line by line: "PAHNAPLSIIGYIR"
Write the code that will take a string and make this conversion given a number of rows:
string convert(string text, int nRows); convert(“PAYPALISHIRING”, 3) should return “PAHNAPLSIIGYIR”.
https://skyyen999.gitbooks.io/-leetcode-with-javascript/content/questions/6md.html
- ::
convert(“PAYPALISHIRING”, 3) P A H N A P L S I I G Y I R
convert(“PAYPALISHIRING”, 4) P I N A L S I G Y A H R P I
P I N A S G Y H P I A R L I
https://github.com/duteng/leetcode/tree/master/Algorithms/ZigZag%20Conversion
def convert(self, s, numRows):
if numRows == 1:
return s
res, gap = "", 2*(numRows-1)
for i in xrange(numRows):
tmp = i
while tmp < len(s):
res += s[tmp]
# special cases
if i != 0 and i != numRows-1:
if tmp+gap-2*i < len(s):
res += s[tmp+gap-2*i]
tmp += gap
return res
556. Next Greater Element III¶
Given a positive 32-bit integer n, you need to find the smallest 32-bit integer which has exactly the same digits existing in the integer n and is greater in value than n. If no such positive 32-bit integer exists, you need to return -1.
Example 1:
Input: 12
Output: 21
Example 2:
Input: 21
Output: -1
给定一个32位正整数n,寻找大于n,并且所含数字与n中各位数字相等的最小32位正整数。若不存在,返回-1。
class Solution(object):
def nextGreaterElement(self, n):
"""
:type n: int
:rtype: int
"""
nums = list(str(n))
size = len(nums)
for x in range(size - 1, -1, -1):
if nums[x - 1] < nums[x]:
break
if x > 0:
for y in range(size - 1, -1, -1):
if nums[y] > nums[x - 1]:
nums[x - 1], nums[y] = nums[y], nums[x - 1]
break
for z in range((size - x) / 2):
nums[x + z], nums[size - z - 1] = nums[size - z - 1], nums[x + z]
ans = int(''.join(nums))
return n < ans <= 0x7FFFFFFF and ans or -1
555. Split Assembled Strings¶
Given a list of strings, you could assemble these strings together into a loop. Among all the possible loops, you need to find the lexicographically biggest string after cutting and making one breakpoint of the loop, which will make a looped string into a regular one.
So, to find the lexicographically biggest string, you need to experience two phases:
Assemble all the strings into a loop, where you can reverse some strings or not and connect them in the same order as given. Cut and make one breakpoint in any place of the loop, which will make a looped string into a regular string starting from the character at the cutting point. And your job is to find the lexicographically biggest one among all the regular strings.
Example:
Input: "abc", "xyz"
Output: "zyxcba"
Explanation: You can get the looped string "-abcxyz-", "-abczyx-", "-cbaxyz-", "-cbazyx-",
where '-' represents the looped status.
The answer string came from the third looped one,
where you could cut from the middle and get "zyxcba".
Note:
The input strings will only contain lowercase letters. The total length of all the strings will not over 1000.
- 这道题的意思是给你一串字符串,你需要把所有子字符串连接在一起。在连接的时候,可以选的反转或者不翻转这个子字符串。这时你有一个长的字符串,这叫一个loop,你可以rotate他来找俺字典排序最大的那个长字符串。解题思路分两步:
- 遍历字符串数组,如果反转的字符串大于当前子字符串,把当前子字符串变成反转的字符串。
- 遍历字符串数组,取得当前字符串和当前字符串的反转字符串,分别比较以当前字符串或者当前字符串的反转字符串为rotate节点的长字符串,取最大的。
- 在第二步的时候可以做优化,如果节点第一个字母小于之前的最大长字符串第一个字母,则可以不比较。代码如下:
553. Optimal Division¶
Given a list of positive integers, the adjacent integers will perform the float division. For example, [2,3,4] -> 2 / 3 / 4.
However, you can add any number of parenthesis at any position to change the priority of operations. You should find out how to add parenthesis to get the maximum result, and return the corresponding expression in string format. Your expression should NOT contain redundant parenthesis.
Example:
Input: [1000,100,10,2]
Output: "1000/(100/10/2)"
Explanation:
1000/(100/10/2) = 1000/((100/10)/2) = 200
However, the bold parenthesis in "1000/((100/10)/2)" are redundant,
since they don't influence the operation priority. So you should return "1000/(100/10/2)".
Other cases: 1000/(100/10)/2 = 50 1000/(100/(10/2)) = 50 1000/100/10/2 = 0.5 1000/100/(10/2) = 2 Note:
The length of the input array is [1, 10]. Elements in the given array will be in range [2, 1000]. There is only one optimal division for each test case.
这道题给了我们一个数组,让我们确定除法的顺序,从而得到值最大的运算顺序,并且不能加多余的括号。刚开始博主没看清题,以为是要返回最大的值,就直接写了个递归的暴力搜索的方法,结果发现是要返回带括号的字符串,尝试的修改了一下,觉得挺麻烦。于是直接放弃抵抗,上网参考大神们的解法,结果大吃一惊,这题原来还可以这么解,完全是数学上的知识啊,太tricky了。数组中n个数字,如果不加括号就是:
x1 / x2 / x3 / … / xn
那么我们如何加括号使得其值最大呢,那么就是将x2后面的除数都变成乘数,比如只有三个数字的情况 a / b / c,如果我们在后两个数上加上括号 a / (b / c),实际上就是a / b * c。而且b永远只能当除数,a也永远只能当被除数。同理,x1只能当被除数,x2只能当除数,但是x3之后的数,只要我们都将其变为乘数,那么得到的值肯定是最大的,所以就只有一种加括号的方式,即:
x1 / (x2 / x3 / … / xn)
这样的话就完全不用递归了,这道题就变成了一个道简单的字符串操作的题目了,这思路,博主服了,参见代码如下:
解法I 数学
在不添加任何括号的情况下:
a / b / c / d / … = a / (b * c * d * …) 在算式中添加括号会使得被除数和除数的构成发生变化
但无论括号的位置如何,a一定是被除数的一部分,b一定是除数的一部分
原式添加括号方案的最大值,等价于求除数的最小值
因此最优添加括号方案为:
a / (b / c / d / …) = a * c * d * … / b
271. Encode and Decode Strings¶
Design an algorithm to encode a list of strings to a string. The encoded string is then sent over the network and is decoded back to the original list of strings.
Machine 1 (sender) has the function: string encode(vector<string> strs) { // … your code return encoded_string; } Machine 2 (receiver) has the function: vector<string> decode(string s) { //… your code return strs; }
So Machine 1 does: string encoded_string = encode(strs); and Machine 2 does: vector<string> strs2 = decode(encoded_string); strs2 in Machine 2 should be the same as strs in Machine 1.
Implement the encode and decode methods.
Note: The string may contain any possible characters out of 256 valid ascii characters. Your algorithm should be generalized enough to work on any possible characters. Do not use class member/global/static variables to store states. Your encode and decode algorithms should be stateless. Do not rely on any library method such as eval or serialize methods. You should implement your own encode/decode algorithm.
本题难点在于如何在合并后的字符串中,区分出原来的每一个子串。这里我采取的编码方式,是将每个子串的长度先赋在前面,然后用一个#隔开长度和子串本身。这样我们先读出长度,就知道该读取多少个字符作为子串了。
249. Group Shifted Strings¶
Given a string, we can “shift” each of its letter to its successive letter, for example: “abc” -> “bcd”. We can keep “shifting” which forms the sequence:
“abc” -> “bcd” -> … -> “xyz” Given a list of strings which contains only lowercase alphabets, group all strings that belong to the same shifting sequence.
For example, given: [“abc”, “bcd”, “acef”, “xyz”, “az”, “ba”, “a”, “z”], Return:
[
["abc","bcd","xyz"],
["az","ba"],
["acef"],
["a","z"]
]
Tip
给定一堆字符串,将移位字符串归类到一起。此处“移位字符串”的定义是将串中所有字符按照a~z的范围循环移位某个固定值,如果两个字符串可以通过移位变成同一串,则互为“移位字符串”。
既然可以任意移位,我们就通过移位把首字符都变成某个固定字母比如a或z,这样就可以将移位字符串聚类了。
def groupStrings(self, strings):
dic = {}
for s in strings:
# "abc"->(0,1,2), "az"->(0,25), etc
tmp = tuple(map(lambda x:(ord(x)-ord(s[0]))%26, s))
dic[tmp] = dic.get(tmp, []) + [s]
return [sorted(x) for x in dic.values()]